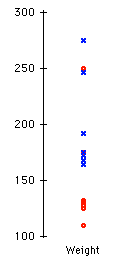Introduction
How much alcohol can one consume before one’s blood alcohol content (BAC) is above the legal limit? Two undergraduate statistics projects, one conducted at The Ohio State University in Columbus, Ohio, and the other at the University of Western Sydney in Sydney, Australia, explored the relationship between BAC and other variables such as amount of alcohol consumed, weight, gender, and age.
Synopsis
Abstract
This example examines the prediction of blood alcohol content (measured from the breath) based on the amount of beer/wine consumed as well as the weight and gender of the individual.
Data Set
Ohio Study: 7 variables, 16 cases
Australian Study: 7 variables, 22 cases
Extensions
Project Ideas.
10 Questions
Experimental design, measurement validity, correlation, regression, examining residuals, transformations
Basic: Q1-10
Protocol
The Ohio State University
The experiment took place in February of 1986 at a student dormitory. Sixteen students volunteered to be the subjects in the experiment. Each student blew into a breathalyzer![]() Breathalyzer:A machine that measures alcohol in the breath and uses that measurement to infer a blood alcohol level. (shown in picture above) to indicate that his or her initial BAC was zero. The number (between 1 and 9) of 12 ounce beers to be drunk was assigned to each of the subjects by drawing tickets from a bowl. Thirty minutes after consuming their final beer, students had their BAC measured by a police officer of the OSU police department. The officer also administered a road sobriety test before and after the alcohol consumption. This involved performing four simple tasks, graded on a scale of 1 to 10 (ten being a perfect rating), demonstrating coordination: balancing on one foot, touching the tip of one’s nose with a forefinger, placing one’s head back with one’s eyes closed, and walking heel to toe. The police officer was not aware of how much alcohol each subject had consumed.
Breathalyzer:A machine that measures alcohol in the breath and uses that measurement to infer a blood alcohol level. (shown in picture above) to indicate that his or her initial BAC was zero. The number (between 1 and 9) of 12 ounce beers to be drunk was assigned to each of the subjects by drawing tickets from a bowl. Thirty minutes after consuming their final beer, students had their BAC measured by a police officer of the OSU police department. The officer also administered a road sobriety test before and after the alcohol consumption. This involved performing four simple tasks, graded on a scale of 1 to 10 (ten being a perfect rating), demonstrating coordination: balancing on one foot, touching the tip of one’s nose with a forefinger, placing one’s head back with one’s eyes closed, and walking heel to toe. The police officer was not aware of how much alcohol each subject had consumed.
University of Western Sydney
In October of 1993, 22 volunteers, mainly university staff and students, attended a lunchtime “cocktail party.” Prior to the start of the experiment, a police officer from the Drug and Alcohol Unit breath-tested all of the participants using a breathalyzer. White wine (10% alcohol/volume) was distributed in 120 ml glasses, and each participant chose his or her own rate of drinking. Snack food and water were available at all times. After 45 minutes participants were told to stop drinking. After waiting an additional 15 minutes each subject was breath-tested again and the number of glasses consumed was recorded for all participants.
Data
The following variables from the OSU and Australia studies are contained in the stored data:
OSU
ID = identification number
Gender
Weight = weight of each subject in pounds
Beers = number of 12 ounce beers consumed
BAC = blood alcohol content
1st-Sobriety = combined score on the four road sobriety tests before alcohol consumption
2nd-Sobriety = combined score on the four road sobriety tests after alcohol consumption
Australia
ID = identification number
Gender
Weight (kg)
Height (cm)
Age
1hr-BAC = BAC after the first hour
Wine = number of glasses of wine consumed during the first hour
Questions
The 1986 OSU Study:
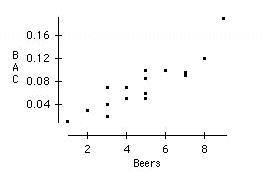
Make a scatterplot of BAC versus number of beers consumed. Do you think the number of beers consumed would be a good predictor of BAC? Why?
The number of beers consumed would be a good predictor because it has a strong relationship with BAC. In general, as the number of beers consumed increases, BAC also increases.
The 1986 OSU Study:
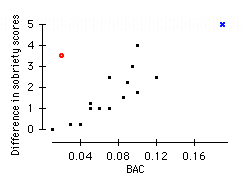
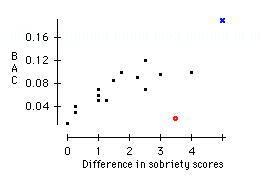
a) For each of the situations below, make a scatterplot showing the relation between BAC and the difference in sobriety scores (you will need to create this variable). Decide which variables should be the independent and dependent variables in each case, and comment on the plots.
b) Which variable is the most valid measure for a police officer “on the street” addressing the following issues? Why? What are the assumptions involved in using even the most valid measures?
Issue 1: What is the true alcohol level in the driver’s blood?
Issue 2: How safely can a person drive a motor vehicle?Variable 1: The number of drinks consumed by an individual.
Variable 2: The BAC measured by a breathalyzer.
Variable 3: The difference between pre and post alcohol consumption sobriety tests.
Variable 4: The sobriety test after suspected alcohol consumption.
a(i)
The independent variable should be BAC, while the dependent variable should be the difference in the sobriety test scores (first test minus second test). In general, the plot shows that as your BAC increases, the deterioration in your coordination increases. However, the plot also shows that there are exceptions to the trend. The red o shows a case where the subject had a very low BAC, but still showed a marked drop in the score on the sobriety test. On the other hand, if we consider removing the blue x, the resulting plot would show a weaker relationship.
a(ii) The independent variable should be the difference between the sobriety test scores, while the dependent variable should be BAC. In general, the plot shows that when a subject's coordination deteriorates, his or her BAC is at a high level. Again, the same exceptions stand out. The red o represents a subject who showed a marked loss of coordination, but registered a very low BAC, and the blue x represents a subject who was unusually high in both variables.
b) For Issue 1, the measurement of choice should be Variable 2, the BAC measured by a breathalyzer. It would be impossible for a police officer who stops a motorist to know the number of drinks an individual has consumed or the difference between the two road sobriety tests. The sobriety test given to an individual after suspected alcohol consumption can be measured, but it measures coordination, not alcohol level. The assumption involved in using the breathalyzer to determine the true alcohol level in the blood is that the machine actually does this! The breathalyzer infers alcohol level in the blood by checking alcohol level in a person's breath.
For Issue 2, the sobriety test given to an individual after suspected alcohol consumption should be preferred, as it measures coordination. The assumption in using this measure, however, is that the coordination skills tested in a sobriety test have something to do with driving coordination skills. In other words, if a person is not able to walk heel to toe, does that give an indication that he would be an impaired driver?
The 1986 OSU Study:
a)Using the OSU data, regress BAC on the difference between the road sobriety test scores. What value of BAC would you predict for a subject who had a difference in sobriety test scores of 2.5? Is this prediction reliable? Explain.
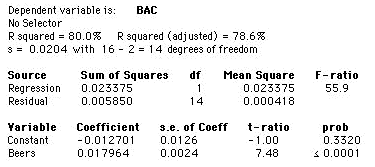
b)Regress BAC on the number of beers consumed. What value of BAC would you predict for a subject who drank 4 beers? Calculate the sample standard deviation of BAC and compare it to the estimate of the standard deviation of BAC about the regression line. Why do the two numbers differ?
c)Which of the two independent variables (i.e. number of beers consumed or difference on road sobriety test scores) is a better predictor of BAC for this data? Why?
a)
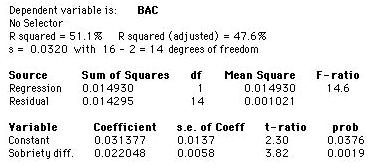
The regression output above indicates the equation for the least-squares line in this setting is
predicted BAC = 0.031377 + 0.022048 × Sobriety diff.
So for a sobriety test score difference of 2.5, we predict
BAC = 0.031377 + 0.022048 × (2.5) = 0.086497.
The value of R2 for this regression is only 51.1%. Thus, there is a good deal of variation in BAC that isn't explained by the difference between sobriety test scores. This indicates that the prediction may not be reliable.
b)
The regression output above indicates that the least-squares line in this setting is
predicted BAC = –0.012701 + 0.017964 × Beers.
So for a subject who drank 4 beers we predict
BAC = –0.012701 + 0.017964 × (4) = 0.059155.
The sample standard deviation of BAC is 0.0441, while the estimate of the standard deviation of BAC about the regression line, s, is 0.0204, less than half as large. This decrease is due to the ability of the number of beers consumed to explain differences in BAC.
c) The number of beers consumed is a better predictor of BAC for this data. Comparing the regression outputs for Question 3 Part a and Part b we see that:
R2 = 51.1% for the regression of BAC on the difference between sobriety test scores
and
R2 = 80.0% for the regression of BAC on the number of beers consumed.
In other words, the number of beers consumed explains more of the variation in BAC than does the difference between sobriety test scores. In addition, a glance at the scatterplots of Question 1 shows that the points in the BAC versus numbers of beers consumed plot are more clustered around a straight line than those in the plot of BAC versus sobriety test scores difference. The higher value of R2 substantiates that visual cue.
The 1986 OSU Study:
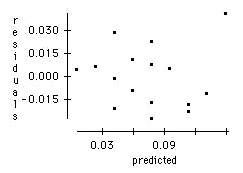
a) Make a scatterplot of residuals versus predicted values for the regression in Question 3 Part b. Does this scatterplot show that there may be problems with the regression?
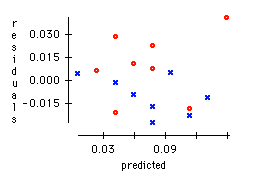
b) For the plot of residuals versus predictors from the regression of BAC on the number of beers consumed mark the points for male and female subjects differently. Do you notice any pattern in the plot when gender is indicated? If so, explain.
a)
Residuals versus Predicted values for the regression of BAC on number of beers consumed.
There is no pattern to this plot. All of the points fall within 2 RMS error (i.e. 2 × (0.0204) = 0.0408) from zero. Thus, this plot does not suggest any problems with the regression.
b) Males are indicated by a blue x in the plot, while females are indicated by a red o. Males tend to have negative residuals, while females tend to have positive residuals. Thus the regression tends to predict too high a BAC for males and too low a BAC for females. This may be due to other factors such as weight.
The 1986 OSU Study:
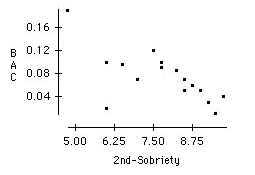
Before the breathalyzer came into widespread use, the road sobriety test was commonly used to decide whether a driver should be cited for drunk driving. Examine the scatterplot of BAC versus the road sobriety test administered after alcohol was consumed to see whether you think the test would be a good predictor of BAC. What could be a problem with its use as a predictor of BAC?
The scatterplot indicates that the road sobriety test administered after alcohol was consumed would not be a good predictor of BAC. In using the road sobriety test score to predict BAC one must take into account that there are differences in natural abilities among subjects. For example, someone who is a dancer may be much better than others at balancing on one foot even if he/she is impaired by alcohol.
The 1986 OSU Study:
a) How could the weight of a person affect your prediction of BAC based on the number of beers consumed by an individual? Give evidence to support your claim. Give a potential confounding factor with respect to how weight affects a person’s BAC.
b) Form a new variable from a ratio of the two variables beers and weight in the following manner. Let the beer-to-weight ratio be:
B/W-ratio = Beers/(Weight + 120.0 lbs)
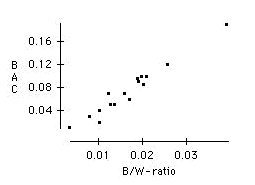
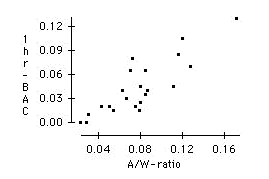
Make a scatterplot of BAC versus the beer-to-weight ratio. Is the beer-to-weight ratio a better predictor of BAC than the number of beers consumed?
c) Regress BAC on the beer-to-weight ratio. Give a prediction of the value of BAC for a subject who drank 3 beers and weighed 140 pounds. Is this prediction reliable? Explain.
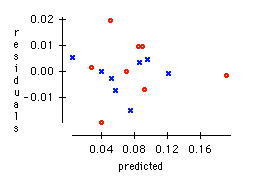
d) Make a scatterplot of the residuals predicted for the regression of Part c. Indicate whether the residual came from a male subject or female subject. Does the scatterplot reveal any potential problems?
e) The scatterplot from Part a of this question reveals one point that is highly separated from the others (i.e. the point with B/W-ratio > 0.03, BAC > 0.16). Remove that point and perform another regression of BAC on the beer-to-weight ratio. Did the regression change much? Comment.
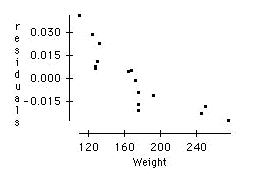
a) A relatively heavy person may consume more beers than a relatively light person and still register a lower BAC. Evidence for this claim may be seen by plotting the residuals from the regression of BAC on the number of beers versus the subject's weight.
The plot reveals that heavy people tend to register a lower BAC than what the regression line would predict, and that light people tend to register a higher BAC than what the regression line would predict.
Gender may also play a role in determining the prediction of BAC since males tend to have a lower BAC than the regression line would predict (see Question 4 Part b), while females tend to have a higher BAC than the regression would predict. Likewise, males tend to be heavier than females, as can be seen in the given dotplot (males are indicated by a blue x, while females are indicated by a red o). That is, the factors of weight and gender are confounded.
b) The beer-to-weight ratio appears to be an even better predictor of BAC than the number of beers. The points in this plot fall very close to a straight line.
c)
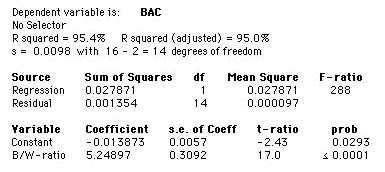
From the output above the regression equation given is:
predicted BAC = –0.013873 + 5.24897 × B/W-ratio
The beer-to-weight ratio for someone who drank 3 beers and weighs 140 pounds is:
B/W-ratio = 3 / (140 + 120) = 0.01154
So the prediction of BAC for the given subject would be:
BAC = –0.013873 + 5.24897 × (0.01154) = 0.0467
This regression is even better than was the regression of BAC on the number of beers consumed. The R2 value of 95.4% shows that the prediction is quite reliable. Note that the intercept is now significantly different from 0 (P-value of 0.0293), but still near 0 in magnitude.
d) The scatterplot doesn't indicate any real problems, although the point with the largest predicted value may be quite influential to the regression (see next question where this is examined further). Note that we no longer have the problem that the residuals for males (marked with a blue x) tend to be negative and the residuals for females (marked with a red o) tend to be positive. The gender effect disappears after controlling for the weight of the subject.
e) The regression with the influential point removed gives the following result:
The regression again gives an excellent fit. The value of R2 changed a bit, but overall the results are more or less the same. The regression equation for this case is:
predicted BAC = –0.014937 + 5.32572 × B/W-ratio.
This is very similar to our equation in Part c. Thus we conclude that this single observation does not influence the fitted regression line much.
The 1993 Australian Study:
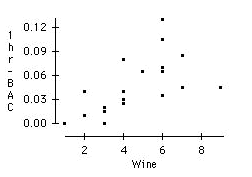
Make a scatterplot of BAC versus the number of drinks consumed in the first hour for the Australian study. Do you think that the number of drinks consumed would be a good predictor of BAC?
While there is definitely a trend in the data (in general as the number of drinks increases so does BAC), the number of drinks consumed doesn't appear to be as good a predictor of BAC as the number of beers was in the previous study. We should also note that as the number of drinks increases, the values of BAC become more spread out, indicating a greater variance in BAC.
The 1993 Australian Study:
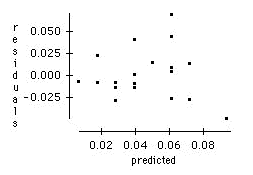
a) Perform a regression of BAC on the number of drinks consumed, and make a scatterplot of the residuals versus the predicted values. Explain how this relates to the scatterplot of Question 7.
b) Predict the value of BAC for a person who drank 4 glasses of wine, and compare your prediction to that of Question 3 Part b. Does the comparison make sense? What differences in the experiments could have caused beers to be a better predictor of BAC in the OSU experiment than number of drinks consumed was of BAC in the Australian experiment?
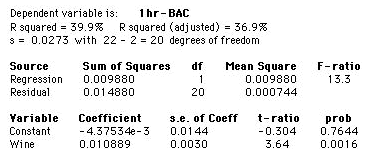
a)
The regression output indicates that the equation for the least-squares line in this setting is:
predicted 1hr-BAC = –0.00437534 + 0.010889 × Wine.
The residuals versus predicted plot shows that the regression suffers from non-constant variance. This potential problem was seen in the scatterplot of Question 7, but is clearer in the residual plot.
b) For a person who drank 4 glasses of wine we would predict
BAC = –0.004375 + 0.010889 × 4 = 0.0479
Comparing this value to the value we found for BAC in Question 3 Part b (calculated for a subject who drank 4 beers) we see that it is lower (0.048 as opposed to 0.059) and that the prediction is less reliable (R2 of 39.9% as opposed to 80.0%). We would not expect the predictions to be exactly the same, or to have the same reliability, as the experimental settings aren't the same for each set of data.
The regression of BAC on the number of beers consumed for the OSU experiment gave a better fit than did the regression of BAC on the number of drinks consumed for the Australian experiment. However, there are a few major differences between the two experiments which we outline below.
The 1993 Australian Study
a) Consider a transformation similar to Question 6 Part b. In particular, let the alcohol-to-weight ratio be:
A/W-ratio = (number of drinks consumed) / (Weight – 20.0 kg).
Make a scatterplot of BAC versus the alcohol-to-weight ratio. Do you think that the alcohol-to-weight ratio will be a better predictor of BAC than the number of drinks consumed is?
b) Perform a regression of BAC on the alcohol-to-weight ratio. Predict the value of BAC that would be obtained for a person who consumed 3 drinks and who weighs 63.63 kilograms (i.e. 140 pounds). Be sure to include a plot of the residuals versus predicted values. Indicate whether the residuals came from a male or female subject.
a) The alcohol-to-weight ratio appears to be a better predictor of BAC than the number of drinks consumed. The points are more tightly clustered around a line than in the scatterplot for Question 7.
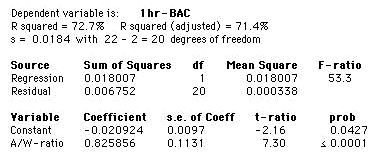
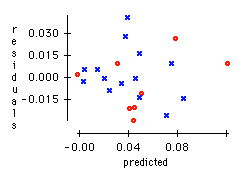
b)
The regression output indicates that the equation for the least-squares regression line in this setting is:
predicted 1hr-BAC = –0.020924 + 0.825856 × (A/W-ratio).
So the predicted value of BAC for a subject who consumed 3 drinks and weighs 63.63 kilograms would be
1hr-BAC = –0.020924 + 0.825856 × (3 / (63.63 – 20.0)) = 0.03586
The value of R2 indicates that 72.2 percent of the variation in the dependent variable is accounted for by the independent variable. The regression gives a very good fit.
The residual plot shows no clear pattern or indication of non-constant variance, nor is there any differing pattern for either males (marked with a blue x) or females (marked with a red o). No potential problems with the regression are revealed by this plot.
Residuals versus Predicted values for the regression of 1hr-BAC on A/W-ratio.
The 1993 Australian Study:
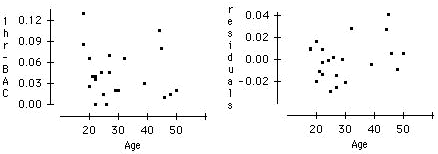
Use plots to examine whether age could be a major factor in determining BAC.
The scatterplot of BAC versus age shows that age is probably not a major factor in determining BAC. The scatterplot does not show either a negative association or positive association of BAC with age. In addition, the scatterplot of the residuals from the regression in Question 9 versus age shows no apparent trend.
Projects
References
Pearl, D. K., and Stasny, E. A. (1992)
Credits
This story was initiated by Nicole DePriest and prepared by Mark Zabel, and last modified on 7/25/95. Thanks to Prof. Kevin Donegan, Univ. of Western Sydney, for the Australian data and Ms. Laura Dowling for data from her Ohio State class project.