Introduction
Many chess masters and chess advocates believe that chess play develops general intelligence, analytical skill, and the ability to concentrate. According to such beliefs, improved reading skills should result from studying to improve chess playing skills. To investigate this belief, Margulies (1993) and Ferguson (1993) conducted several studies, one of which is examined here. Subjects in the study participated in a comprehensive chess program, and their reading performances were measured.
Synopsis
Abstract
A study is presented to explore whether improving chess ability will also improve reading ability. The design consisted of a reading pre-test, a year of chess instruction, and then a reading post-test.
Data Set
3 variables, 53 cases
4 Questions
Graphical analysis, descriptive statistics, normal probability plots, simple random samples, confounding factors, control groups, populations, hypothesis testing, outliers.
Basic: Q1-3
Semi-tech: Q4
Protocol
First Year Study
This study took place from November, 1990 to May, 1991. Students who had taken a Degree of Reading Power Test (DRP), had scored in at least the 10th percentile, and had participated in the 1990 District Nine Chess Tournament were selected to receive chess instruction after school. Instruction and inspiration were given by the teacher, and by chess masters.
Second Year Study
This study took place from November, 1991 to May, 1992. Second year subjects were chess team members in a computer-enhanced program. In addition to receiving general chess instruction after school they also were able to practice against computer chess software and could play matches against remotely located opponents via modem.
Subjects in both the first and second years of the study were voluntary participants.
The reading test scores used in this study were the percentile scores on the DRP test. The DRP test is designed so that the average reading student in, for example, 4th grade scores at the 50th percentile. If this student continues to improve in reading proficiency at an average rate throughout the school year, he or she will be an average reader in the 5th grade and once again score at the 50th percentile.
Data
The following variables are contained in the stored data:
ID = student identification number
Pre-Score = DRP test score in the year prior to the student's entering the program
Post-Score = DRP test score one year following the pre-score
Questions
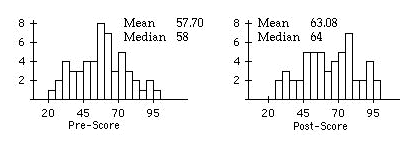
a) Make histograms of the pre-and post-DRP test scores, comment on their shapes, and report both the mean and median for the pre-and post-DRP test scores. Was there an overall improvement in the DRP test scores for the subjects in this study after taking the chess course?
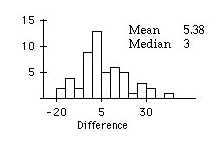
b) Make a new variable of the difference between the post-DRP test scores and the pre-DRP test scores. Calculate appropriate summary statistics for the differences and make a histogram of the data. Do your calculations indicate a general improvement in DRP reading scores for the subjects in this study after receiving the chess instruction? Comment on any interesting features of this histogram. Why is the mean larger than the median for these differences?
a) The means and medians of the post-scores are both larger than the means and medians respectively of the pre-scores. The histograms are both roughly symmetric and show that there were more low scores on the pre-test than on the post-test. The subjects did show an improvement in DRP test scores on the post-test.
b) Both the mean and the median are greater than zero, which indicates that there is an overall improvement in the DRP test scores for the subjects. The histogram also appears to be slightly skewed right. It is this that makes the mean larger than the median. The histogram indicates, however, that not all of the students who took the chess course improved their reading skills.
Make a normal probability plot of the differences between the pre- and post-DRP test scores and comment on any outstanding features of the plot.
The normal probability plot shows that differences between pre- and post-DRP test scores somewhat follow the normal curve. However, the plot also reveals the presence of a slight outlier corresponding to the rightmost bar in the histogram, and again reveals the distribution is skewed right.
a) Was the sample taken in this study a simple random sample? Explain.
b) Give an example of a possible confounding factor in this study, and suggest an appropriate control group which would take this into account.
c) To what population can inference based on the results of this study be made?
a) It was not a simple random sample. Subjects volunteered to participate in the study. Also, students with DRP scores below the 10th percentile were excluded from the study.
b) It is possible that the students’ reading scores improved because they were getting extra attention from an adult. An appropriate control group might be a similar sample of students who, under the supervision of a teacher, would get together after school to engage in some activity not thought to affect reading, say to listen to classical music.
c) The subjects were not a simple random sample from the population of all grade school students. There is some selection bias in favor of eager students who are willing to give up some time after school in order to participate in the chess instruction. Thus, we should not make conclusions about the effect learning chess will have on all students' reading scores.
a) Use a statistical test on the differences between pre- and post-DRP test scores to test whether there was an improvement in DRP scores after chess instruction. State your hypotheses, report the value of your test statistic, and give the P-value for the test. Provide your conclusions (both statistical and subject matter), and discuss the validity of the assumptions of the test you have chosen.
b) Remove the data point which has a difference between pre- and post-DRP test scores equal to 42 (it is a mild outlier and we wish to see how it affects our results) and repeat the test of Question 4 Part a. State your hypotheses and report the value of your test statistic, the P-value for the test, and your conclusions. Compare your results here to those of Question 4 Part a. Did removing the outlier change your results? Comment.
H0: Chess instruction does not improve DRP test scores.
versus
Ha: Chess instruction does improve DRP test scores.
Using the one-sample t test we find that t = 3.007 with 52 degrees of freedom. This gives a P-value = 0.002. Thus, we would reject the null hypothesis. There is strong evidence that given a similar sample of students, taking an administered, programmed chess course, we would likely see a rise in the overall average DRP test score of the group.
The result of a one-sample t test is exactly correct only when the population is normally distributed. In Question 2 we found that the data indicated that the population was not normal. However, the t test is robust against non-normality, as the distribution of the sample mean from a large sample is close to normal (central limit theorem) and the sample standard deviation approaches the population standard deviation as the sample size gets large. In this case we have a relatively large sample, so the violation of the normality assumption isn't so serious. A z test is also a reasonable procedure in this case. The t test and z test are not robust against extreme outliers, however, since they are based on the sample mean. Since we only have a mild outlier, we wouldn't expect the results to change too much upon its removal. This is examined in Question 4 Part b. Finally, it would also be reasonable to use a nonparametric procedure such as the sign test here.
b) Again, we wish to test
H0: Chess instruction does not improve DRP test scores.
versus
Ha: Chess instruction does improve DRP test scores.
Using the one-sample t test we find that t = 2.778 with 51 degrees of freedom. This gives a P-value = 0.0037. Thus, we would reject the null hypothesis. The conclusion of this test is the same as the conclusion of the test done in Question 4 Part a, but the value of t is smaller and the P-value is higher. This is consistent with the fact that the outlier was a maximum and tended to support the alternative hypothesis.
Though the conclusions were the same in this case, one should always be concerned with the presence of outliers when relying upon the results of a t test. The t test is sensitive to outliers because it is based on the sample mean and sample standard deviation, both of which are quite sensitive to outliers. In this case, the relatively large sample size acted to diminish the effect of the outlier.
References
Ferguson, R. (1993)
Margulies, S. (1993)
Credits
This story was prepared by Mark Zabel and last modified on 2/22/95.